第四章_Pepper识图
转载 2020-08-12 11:10 京天机器人 来源:京天机器人本系列讲义是《人工智能》课程配套讲义,结合教学一线实践课程编写而成。
一共分为10个章节,总学时数32课时,各院校课根据教学实际情况灵活安排,人工智能科普学习或者兴趣班的课程可以安排16课时,作为专业课程学习可以安排64学时,多一些动手实践和创新环节。
| 教学章节 | 建议课时数 | 知识点 |
| 第一章 初识pepper与人工智能 | 2 | 了解人工智能的发展历史、基本概念、专业术语以及典型应用 以pepper机器人为载体,理解模式识别与机器学习 建立起科学、客观的人工智能发展观 |
| 第二章 pepper聚类 | 3 | 了解聚类的概念和方法 掌握K-means算法和DBSCAN算法 实践基于pepper机器人聚类算法验证 (学习成绩聚类) |
| 第三章 pepper分类 | 3 | 了解分类的概念和方法 掌握K近邻(KNN)算法和支持向量机(SVM)算法 实践基于pepper机器人分类算法验证(统计学习成绩) |
| 第四章 pepper识图 | 4 | 了解图像识别技术、人工神经网络、深度学习 掌握BP神经网络并在机器人上验证算法 掌握通用文字识别技术并在机器人上实践 掌握人脸识别技术并在机器人上实践 |
| 第五章 pepper读书 | 4 | 了解了词频(TF)、TF归一化、文档频率(DF)、TF-IDF等文本特征统计方法 掌握余弦相似度和欧氏距离这两种基本的度量方法 使用Jieba分词、文章关键词的提取、文章相似度分析并在机器人上验证算法 |
| 第六章 pepper听音乐 | 4 | 理解语言合成概念及原理 理解语音识别概念及原理 理解自然语义理解NLU与知识库、关键字识别 了解声音波形图 使用pepper进行语音识别 |
| 第七章 pepper看视频 | 4 | 了解视频识别和图像识别的联系与区别 掌握了卷积神经网络基本结构及各层的作用 理解卷积神经网络 使用pepper进行人脸表情识别、视频内容分析 |
| 第八章 人机对话 | 5 | 了解人机对话概念、感知方式与触发模式、人机互动等基础知识 理解多通道决策的方式方法及多模态信息融合 使用pepper体验人机对话 使用pepper进行人机互动 |
| 第九章 pepper带你探索数字世界 | 2 | 了解pepper机器人的行走、动作、胸口屏幕的技术实现和可能应用 了解人工智能时代下的智慧场景中pepper的应用可能:智慧养老等 使用pepper进行地图扫描,SLAM 使用pepper完成数字互动技术 |
| 第十章 科技与信息安全和伦理道德 | 1 | 了解信息安全和伦理道德规范 拥有网络和数据安全意识 |
| 合计 | 32 |
本讲义以“pepper”机器人为主要教学载体工具,以Choregraphe为主要开发软件平台(支持Python和图形化编程),聚焦学习和实践人工智能技术应用领域中的语音识别、图像识别、文本识别、视频识别等基础技术知识,在教学过程中,穿插神经网络、机器学习、自然语言理解等关键知识点,并以机器人流程自动化(Robot Process Automation)将机器人和智能数字世界串联起来形成场景化应用,采用讲练结合和任务驱动的教学方式,以帮助学生能够直观而准确地了解和学习人工智能的相关知识。



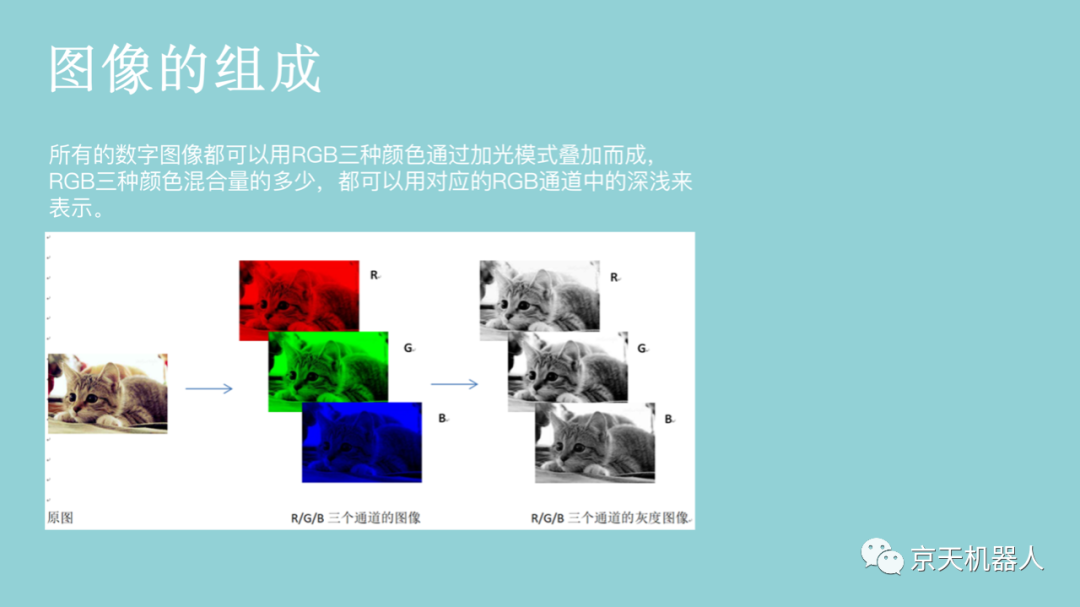

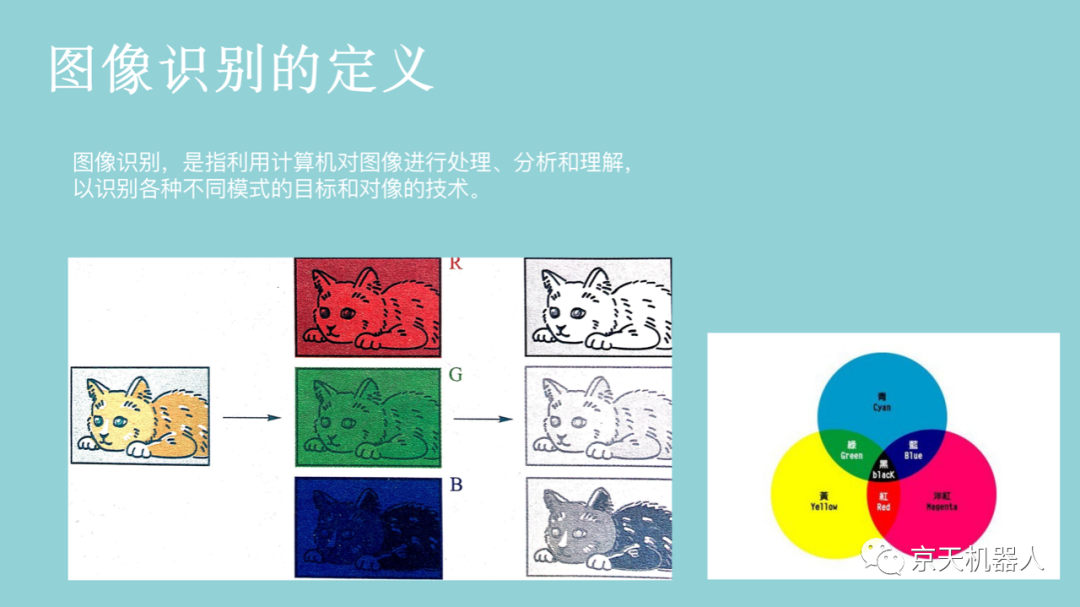
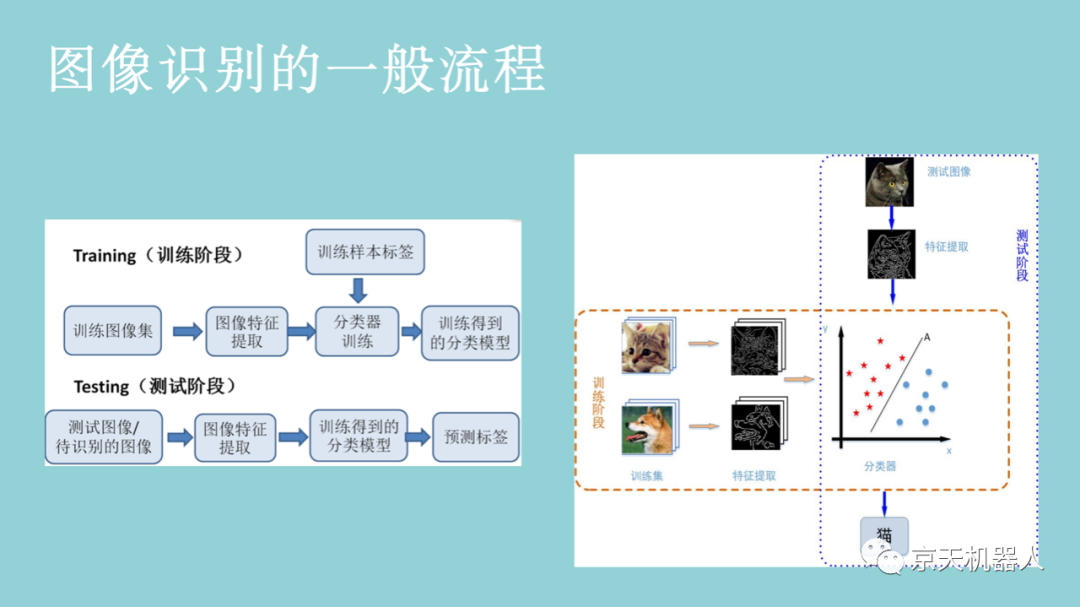
图4-5则是以猫和狗为识别目标的一个图像识别系统。系统需要一些猫和狗的图像,通过这些图像学习出猫和狗各自的特征(例如猫和狗的轮廓不一样),再通过对猫狗特征的学习获得能够分辨猫狗的分类器。在训练好猫狗分类器以后,当有新的猫或者狗的图像输入到系统时,系统首先将图像转换成特征,然后使用已经学习好的猫狗分类器就能自动识别出是猫还是狗。需要注意的是,系统只能对已经学习过的类别进行识别。例如,识别系统只训练学习了狗和猫的图像,那么该系统只能识别狗和猫的图像。如果你给这个系统一只狐狸的图像,该系统则无法识别。
通常,输入的原始图像有太多冗余的信息,而这些信息不是分类所必需的。因此,图像分类的第一步是通过提取包含在图像中的重要信息并舍弃其余部分来简化图像。例如,我们可以通过使用边缘检测器,将图像中物体的边缘信息提取出来。该步骤称为特征提取。在传统的计算机视觉方法中,设计这些特征对算法的性能是至关重要的。除了简单的边缘特征以外,我们可以进一步提取其它更有用的特征。常用的图像特征包括Haar特征、HOG(Histogram of Oriented Gradients)特征、SIFT(Scale-Invariant Feature Transform)特征、SURF特征(Speeded Up Robust Feature)等。一旦获取了图像特征,我们就可以通过前面章节所学的分类学习方法对图像进行分类。图像识别常用的分类学习方法主要包括支持向量机、最近邻分类器、人工神经网络、深度学习等。

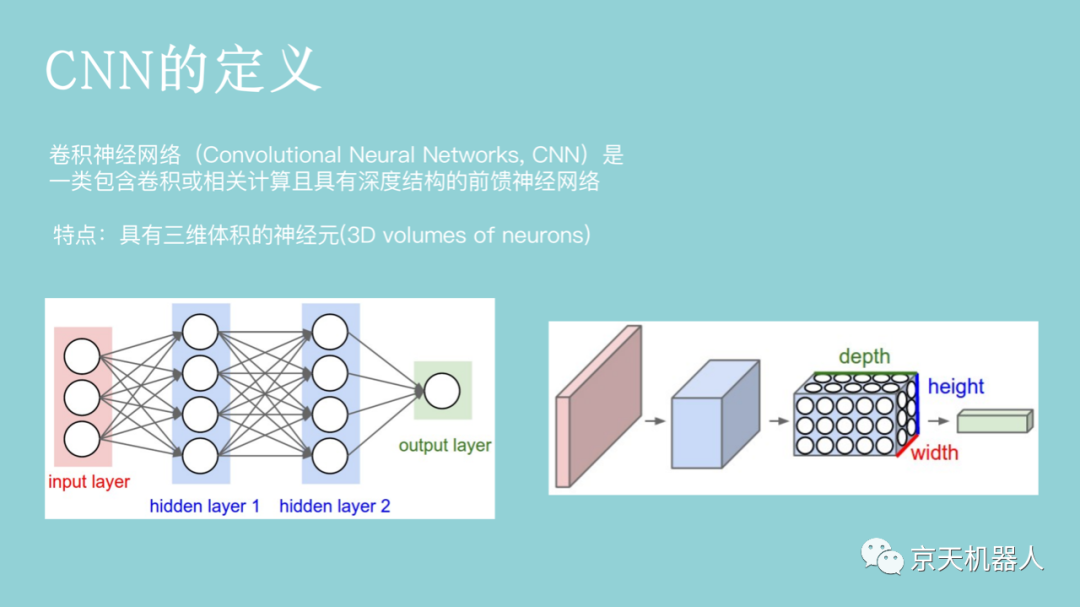

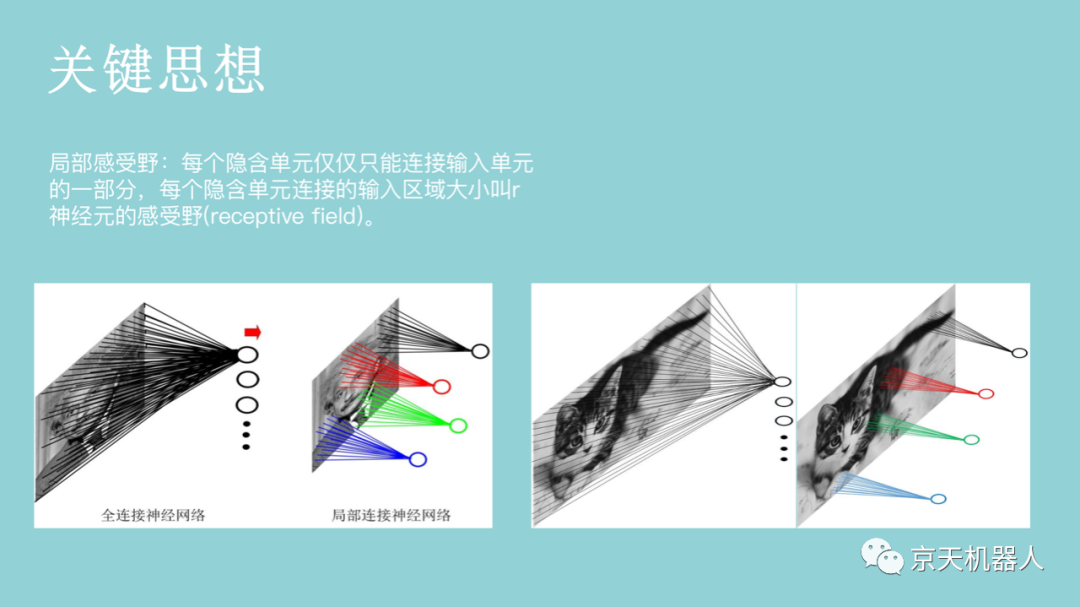
对于一个1000 × 1000的输入图像而言,假设采用上一节所讲述的每个神经网络都和前面一层的所有神经元相连的前馈神经网络(全连接神经网络),如果下一个隐藏层的神经元数目为10^6个,则输入层和隐含层之间的权值参数有1000 × 1000 × 10^6 = 10^12之多,如此数目巨大的参数几乎难以训练。在卷积神经网络中,为了减少权值参数的个数,提出了局部感受野(local field)这一概念。一般认为,人对外界的认知是从局部到全局的,图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知(也就是说,神经元没有必要和下一层的所有神经元相连,只需和下一层的部分神经元相连),然后在更高层将局部的信息综合得到全局信息。如果采用局部连接,假设隐藏层的每个神经元仅与图像中10 × 10的局部图像相连接,那么此时输入层和隐含层之间权值参数数量为10 × 10 × 10^6 = 10^8,与传统的前馈神经网络相比,参数个数直接减少4个数量级。
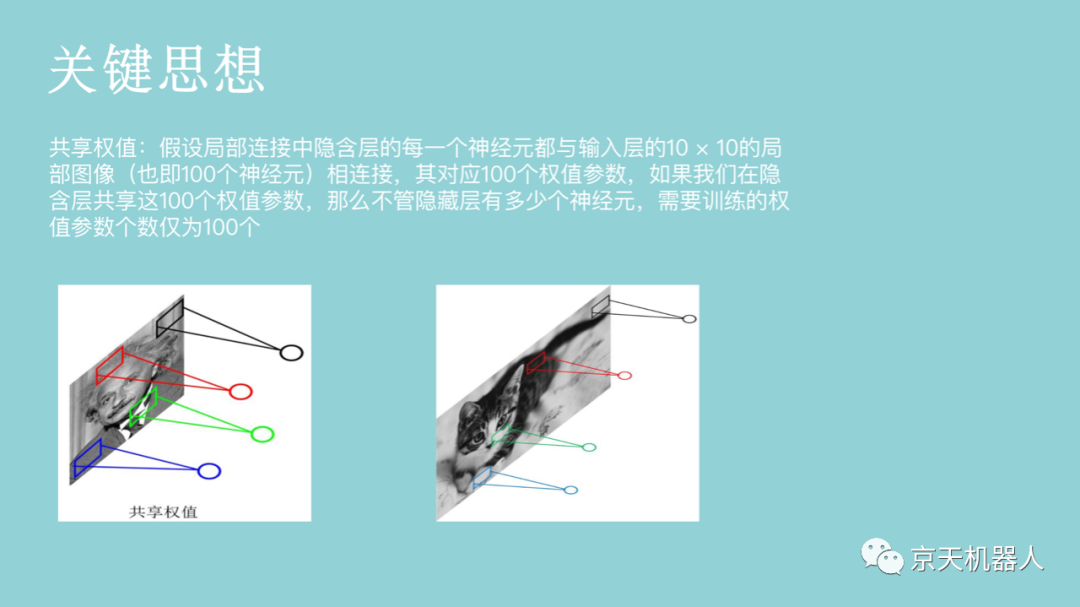
卷积操作可以看成是提取特征的方式,不同的卷积核能够得到图像的不同映射下的特征,称之为特征映射(Feature Map)。如果把一个卷积核看成提取一种特征,那么我们可以通过使用多个不同的卷积核来达到提取多个特征的目的。如果有64个卷积核,那么就可以提取64种特征,两层之间的权值参数也仅为100×64= 6400个。
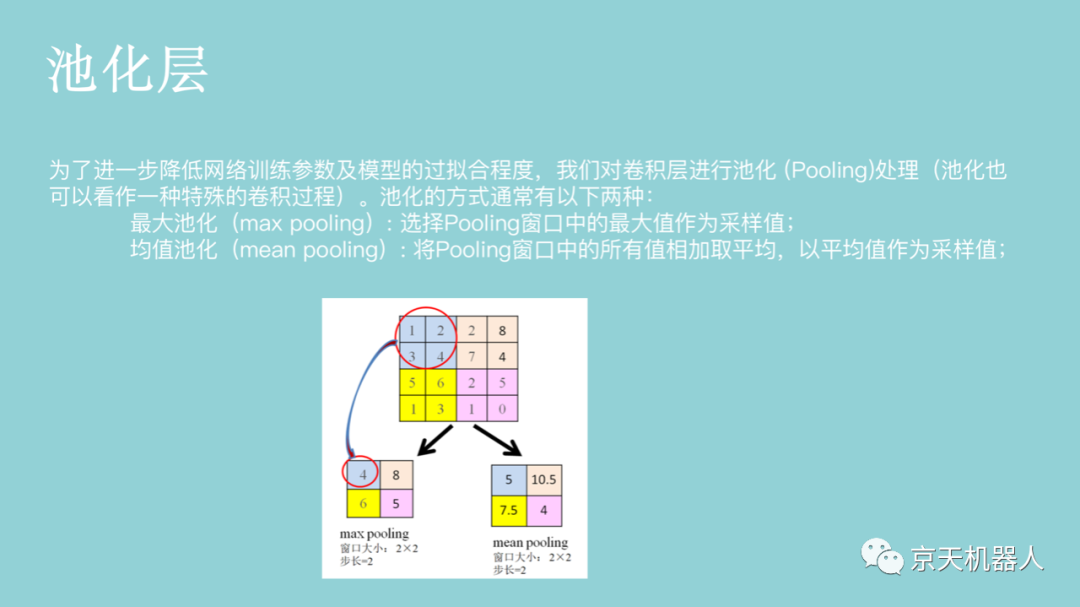

图像识别能够解决的问题,也是从一开始只能识别一些简单的图像,到现在能够识别较复杂的场景,但是离人类对图像内容的全面理解还有很长的一段距离。



感谢NPLUS AI教育研究团队出版的相关书籍并提供的教学指导帮助。



相关资讯
更多- 中国AGV网上周热点回顾(2026年6月15日-6月20日)
- 中国AGV网上周热点回顾(2026年6月8日-6月13日)
- AGILOX × 上交会 | 6.11-13
- 中国AGV网上周热点回顾(2026年6月1日-6月6日)
- “一带一路 出海向新丨中叉网/AGV网2026亚欧大陆万里行” 圆满收官
- 第三届中国工业车辆和移动机器人“金力奖”颁奖盛典圆满落幕
- 中国AGV网上周热点回顾(2026年5月25日-5月30日)
- 中叉网/AGV网网将再度亮相LET 2026,共筑智慧物流新未来
- 中国AGV网上周热点回顾(2026年5月18日-5月23日)
- 中国AGV网上周热点回顾(2026年5月11日-5月16日)