CoRL 2025新作:从“看”到“触”,TA-VLA实现机器人触觉智能跃迁
转载 2025-12-19 09:52 松灵机器人 来源:松灵机器人
想象一个看似简单的任务:把充电头插进插座。对人类来说,我们不仅用眼睛看,还会用手感受阻力——插歪了会卡住,插到位会有“咔哒”感。这种力觉反馈是完成精细操作的关键。
但在当前主流的视觉-语言-动作(Vision-Language-Action, VLA)模型中,机器人只依赖摄像头和指令,完全忽略了来自关节的扭矩信号。这就导致它们在面对“接触密集型”任务(如按按钮、拧门把手、插拔接口)时,常常失败却不知为何。
使用产品:松灵PiPER六轴机械臂
论文链接:https://arxiv.org/pdf/2509.07962v1
论文作者:Zongzheng Zhang, Haobo Xu, Zhuo Yang, Chenghao Yue, Zehao Lin, Huan-ang Gao, Ziwei Wang, Hao Zhao
项目主页:https://zzongzheng0918.github.io/Torque-Aware-VLA.github.io/(论文收录至CoRL 2025)
01
让扭矩成为机器人的“第六感”
传统VLA模型(如 π0、RDT、Octo)主要依赖视觉+语言+关节位置进行决策。但这些信号在接触发生时往往变化微弱,难以判断操作是否成功。
而关节扭矩(joint torque)——即电机输出的力矩——能直接反映末端执行器与环境的物理交互状态。例如,在“接充电头”任务中(见下图):
未接触:扭矩平稳;
接触但未接入(插歪):小幅波动;
成功接入:出现明显、尖锐的扭矩峰值。
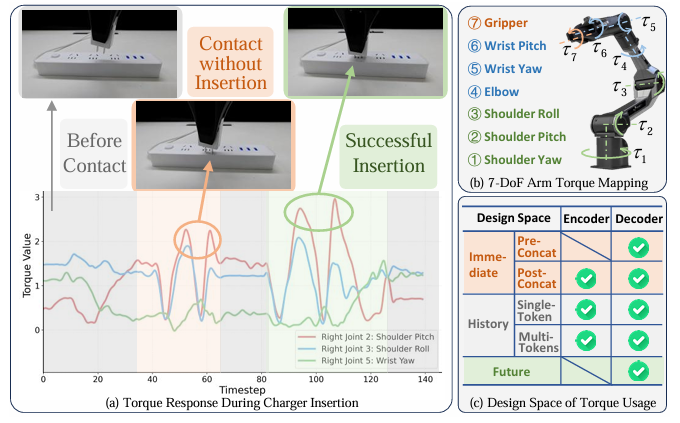
研究团队发现:仅靠视觉,模型无法区分“接歪”和“接好”;但加入扭矩信号后,判别变得清晰可靠。
02
三大关键设计发现
该工作不仅提出方法,更系统探索了扭矩信号如何有效融入VLA模型的设计空间,得出三条重要原则:
扭矩应注入解码器,而非编码器
原因:扭矩与关节角度同属本体感知信号(proprioception),在动作生成阶段(即解码器)融合,能更好利用其与动作的强相关性。
验证:通过HSIC(希尔伯特-施密特独立性准则)分析,发现扭矩特征与关节角度高度对齐,远超与图像或文本的关联。
历史扭矩比单帧更重要,但需压缩为单个Token
真实数据的纹理、光照、视角等维度多样性有限,导致模型在新环境中易失效;
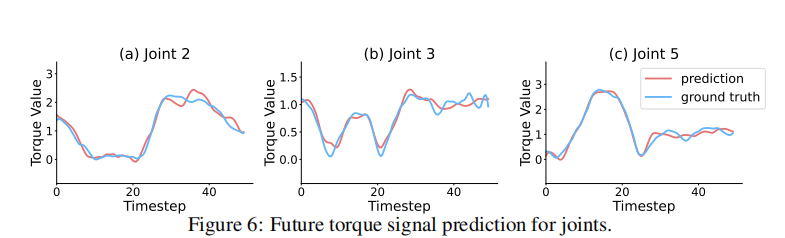
预测未来扭矩,可构建物理感知的内部表征
受自动驾驶中“联合预测轨迹与意图”启发,团队提出动作-扭矩联合扩散模型:
模型不仅预测未来动作序列,同时预测对应的扭矩序列;
通过辅助损失监督扭矩预测,迫使模型理解“动作→力反馈”的因果关系;
实验显示,模型能准确预测未来50步的扭矩变化(见下图),显著提升接触任务成功率。
03
实验结果:全面超越现有VLA模型
团队使用AgileX PiPER Arm在10个真实世界任务(5个接触密集型 + 5个常规任务)上进行了测试,包括:
充电器/USB插拔
按钮按压
门把手旋转
瓶子抓取、倒水、叠积木等



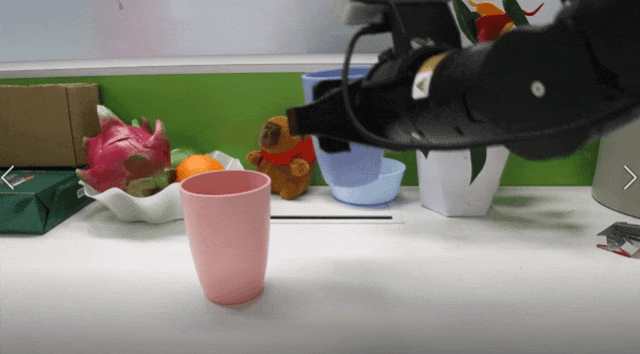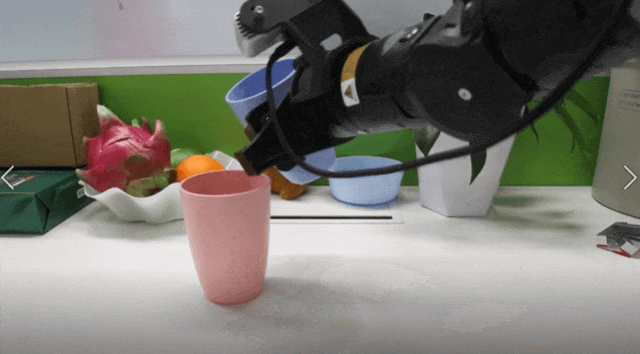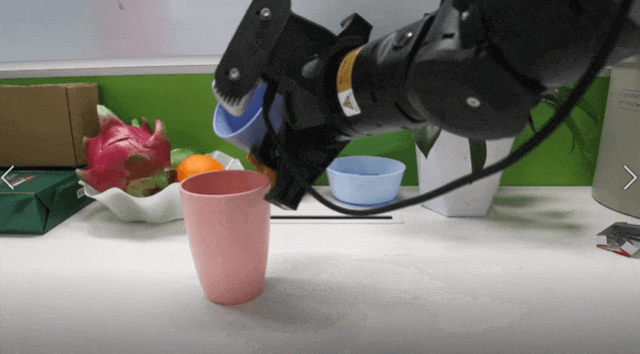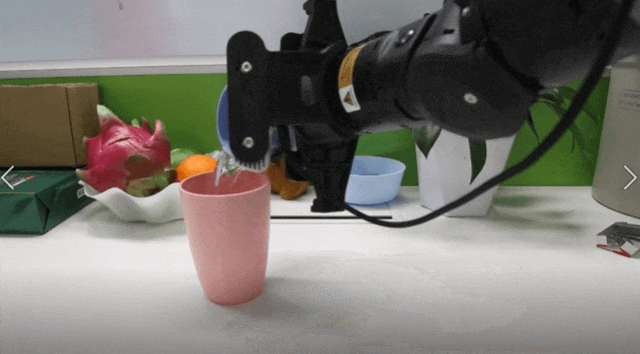
以当前最强VLA模型 π0为基线,TA-VLA(即 π0+obs+obj)在接触任务上的平均成功率从不足5% 提升至超80%!
| 方法 | 按钮按压 | 接充电器 | 接USB | 开门把手 |
| π0 | 5/20 | 0/20 | 0/20 | 2/20 |
| TA-VLA | 18/12 | 17/20 | 17/20 | 15/20 |
更令人惊喜的是,即使在非接触任务中(如倒水、开抽屉),引入扭矩信号也能带来小幅提升,说明物理感知具有泛化价值。
此外,该方法在 RDT、ACT 等其他VLA架构上同样有效,并成功迁移到不同品牌机械臂(如ROKAE SR),展现出强大的跨模型、跨本体泛化能力。
03
意义与展望
TA-VLA 的工作标志着VLA模型从“纯感知-决策”迈向“感知-力觉-决策”的新阶段。它证明了:
无需昂贵外置传感器,仅利用机器人自带的关节扭矩即可实现高精度接触感知;
预训练VLA模型具备良好扩展性,可高效融合新模态;
物理信号不仅是输入,更是学习目标——通过预测扭矩,模型能内化物理规律。
相关资讯
更多- 邀请函 | 华睿科技机器视觉生态大会·杭州站
- 新华社权威关注|AITEN 聚焦工业真实场景,让智能智造落地千行制造
- 高温高湿下,电池如何安然度夏?
- 合力 |【奋斗者说】第九期:先锋·引领
- 产能全面跃升!德马未来超级工厂投产,激活全球项目履约新动能
- AGV和RGV有何区别?
- 10款叉车同步更新:Manitou以锂电与内燃双路线重构工业车辆产品组合
- Brightpick与TREW建立合作:货到人机器人与北美系统集成能力加速结合
- Dexterity与Kawasaki扩大合作:Physical AI开始瞄准高强度仓储装卸
- Rockwell推出FactoryTalk Orchestration:把机器、人员和物料移动纳入统一编排