开源!LingBot-VLA:2 万小时数据训练的通用VLA
转载 2026-01-31 09:15 松灵机器人
在机器人操控领域,一个能跨任务、跨平台灵活适配,还兼顾成本效益的视觉-语言-动作(VLA)模型,一直是行业追求的目标。
28日,蚂蚁灵波科技开源具身大模型 LingBot-VLA,凭借海量真实数据训练、卓越的泛化能力和超高训练效率,为机器人通用化操控带来了全新突破。
01 三大优势领跑VLA模型赛道

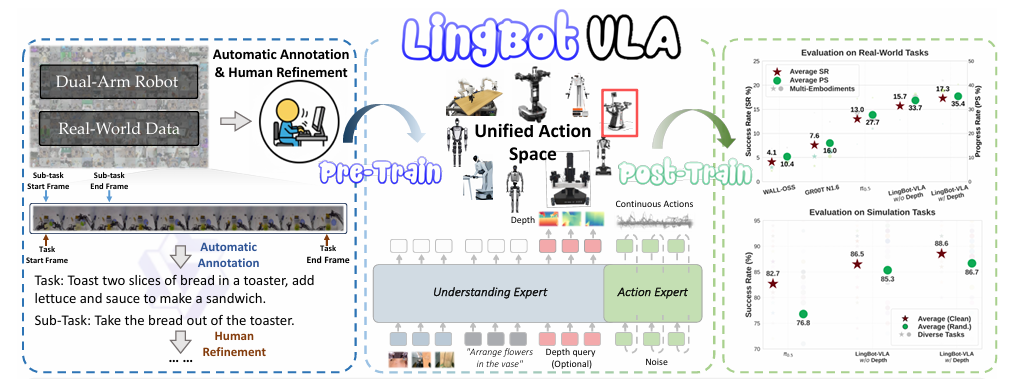
LingBot-VLA的底气,来自于包括AgileX C OBOT MAGIC在内的9种主流双臂机器人构型的真机操作数据。团队累计采集了近2万小时的真实世界操控数据,涵盖摆盘、插花、拧螺丝等多样化任务场景。
不同于以往依赖仿真数据的模型,LingBot-VLA的训练数据全部来自真实机器人操作。这让模型学到的技能更贴近实际应用需求。更关键的是,实验证明随着数据量从3000小时提升到20000小时,模型下游任务成功率持续增长,没有出现饱和迹象。这意味着更多数据还能持续赋能模型性能。
02 真实场景超能打
为验证模型的真实能力,团队搭建了严苛的测评体系。他们选取AgileX COBOT MAGIC等三款主流机器人平台,用包含100个精细任务的GM-100基准测试集开展测试。
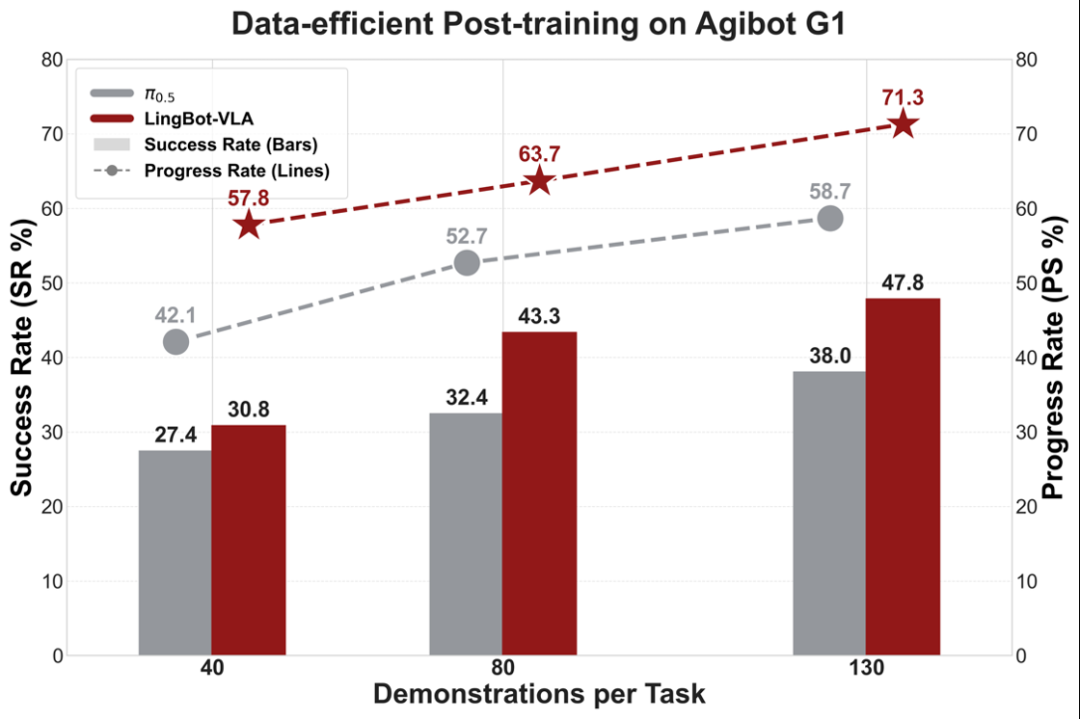
实验表明,LingBot-VLA 在下游任务中能够使用更少的数据,达到超越π0.5的性能;并且性能优势会随着数据量的增加而持续扩大。目前,LingBot-VLA 已与松灵等机器人厂商完成适配,验证了模型在不同构型机器人上的跨本体迁移能力。
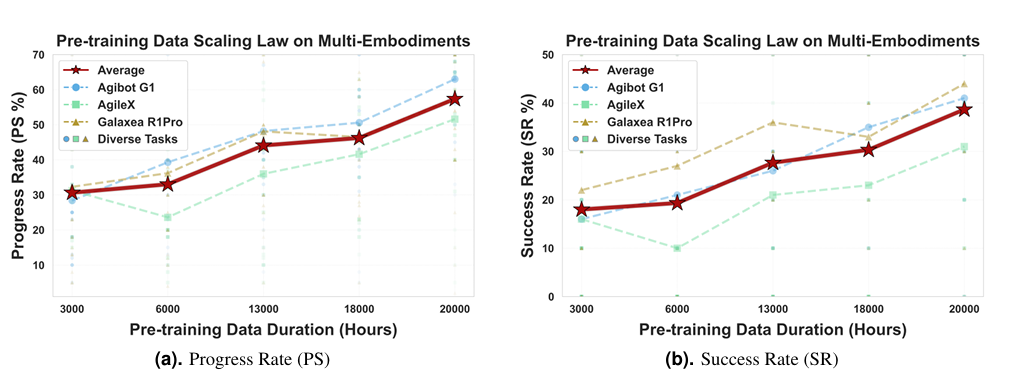
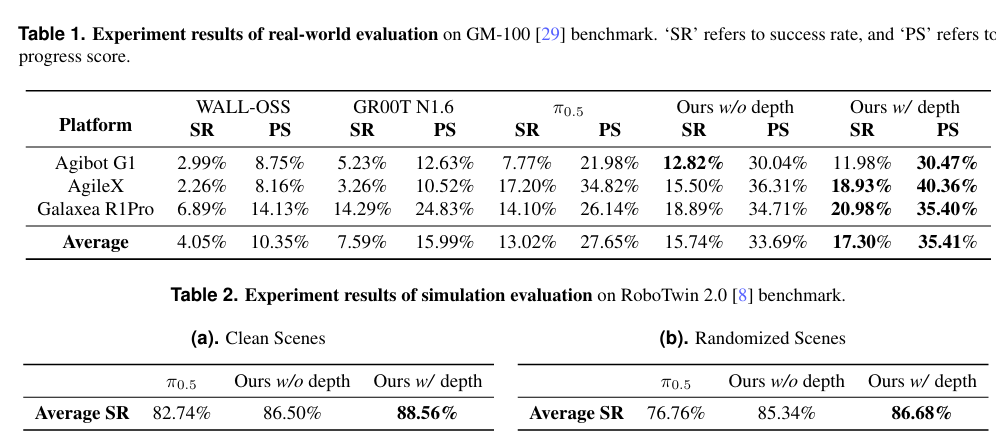
这组数据充分证明,LingBot-VLA不仅能在实验室“跑分”,更能在真实场景中稳定输出。
03 训练效率狂飙1.5-2.8倍,省钱又省时
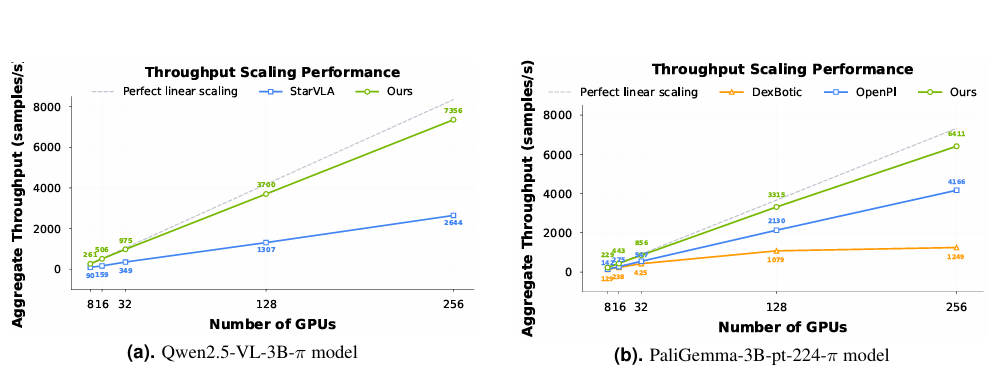
大模型训练的算力成本一直是行业痛点,而LingBot-VLA在这方面也交出了高分答卷。
团队开发了一套高度优化的训练代码库。在8卡GPU集群上,这套代码库能实现单卡每秒261个样本的吞吐量。相比现有的VLA专用代码库,训练速度提升了1.5-2.8倍。
效率提升的秘诀在于两点:
一是采用分片数据并行策略,大幅降低显存占用和通信开销;
二是通过算子融合、灵活注意力机制优化,减少计算冗余。这让模型训练周期大幅缩短,部署成本显著降低。
04 LingBot-VLA的底层架构
LingBot-VLA的出色表现,离不开精心设计的技术架构:
1. 混合Transformer架构:模型以Qwen2.5VL预训练视觉语言模型为基础,搭配独立的“行动专家”模块。两种模态通过共享注意力机制协同工作,既保证语义理解能力,又能精准生成机器人行动指令。
2.连续行动建模:采用流匹配(Flow Matching)技术,让机器人生成的动作更流畅平滑。这避免了机械臂“卡顿”“抖动”等问题。
3.空间感知增强:通过视觉蒸馏技术,将深度信息融入模型。这弥补了传统VLA模型空间推理能力的短板,让机器人在抓取、堆叠等精细操作中更精准。

05 开源共享:推动机器人学习领域共同进步
此次开源,Robbyant团队不仅提供了模型权重,还同步开放了包含数据处理、高效微调及自动化评估在内的全套代码库。Robbyant团队希望这一举措可以大幅压缩模型训练周期,降低商业化落地的算力与时间门槛,助力开发者以更低成本快速适配自有场景,提升模型实用性。
基于领先的LingBot-VLA模型,松灵也将与蚂蚁灵波科技继续携手,探索更多商业场景的落地应用,促进具身基础模型生态发展。
目前Robbyant团队的模型、后训练代码、技术报告、以及和上海交大共同打造的 GM-100 Bench-mark已全部开源,欢迎大家访问Robbyant团队的开源仓库。
相关资源可通过以下链接获取:
项目主页:
https://technology.robbyant.com/lingbot-vla
模型:
https://huggingface.co/collections/robbyant/lingbot-vla
https://www.modelscope.cn/collections/Robbyant/
LingBot-VLADatasets:
https://huggingface.co/datasets/robbyant/lingbot-GM-100
代码仓库:
https://github.com/Robbyant/lingbot-vla
项目论文:
https://arxiv.org/abs/2601.18692
相关资讯
更多- 重磅!镭神智能斩获上海市科学技术奖一等奖,自研 1550nm 光纤探测激光雷达兼顾海上作业与反无人船双重应用
- 爱动超越赋能先进制造高质量发展,双案例入选2026全球数字经济大会AI典型案例,树立全国"AI+先进制造"标杆样本
- 风雨无阻 千里驰援丨三一服务从不缺席
- 你的物流差的不是自动化,是可扩展性
- 优必选与申昊科技签署战略合作协议,人形机器人加速落地电力行业优必选科技
- 邀请函 | 聚焦数智物流装备,迈睿机器人邀您共聚青岛APIE2026
- 通用“眼+脑”即将亮相2026越南工业科技展,梅卡曼德邀您共见精密智造新突破
- AI时代算力密度狂飙,电力底座如何“极限跨越”?
- 朗誉展讯|朗誉将亮相第 16 届新疆矿博会,无人重载运输车荣获官方优秀品牌认证!
- 展会邀约|2026世界人工智能大会