清华大学&天创&阿里达摩院联合发布具身智能VLSA全新架构
转载 2025-12-17 11:01 天创机器人 来源:天创机器人
在大模型驱动的具身智能浪潮中,VLA(Vision-Language-Action)模型凭借强大的语义理解与任务泛化能力,正成为下一代通用机器人的核心引擎。但现实很骨感:“听得懂”不等于“做得对”,更不等于“做得安全”。许多VLA系统在仿真中表现惊艳,一旦部署到真实环境,却因缺乏对物理世界的“敬畏之心”而频频“硬碰硬”--轻则打翻物料、中断任务,重则损坏工厂设备、危及人员。越聪明的模型,潜在风险反而越高。
面对这一“落地最后一公里”的关键瓶颈,清华大学安全控制技术研究中心、天创机器人与阿里达摩院联合提出全新解决方案:VLSA(Vision-Language-Safe Action)架构--无需重训现有VLA模型;无需修改任何原始参数;即插即用嵌入动作输出端,即可为其叠加一层可验证、可量化、低延迟的安全保障层!
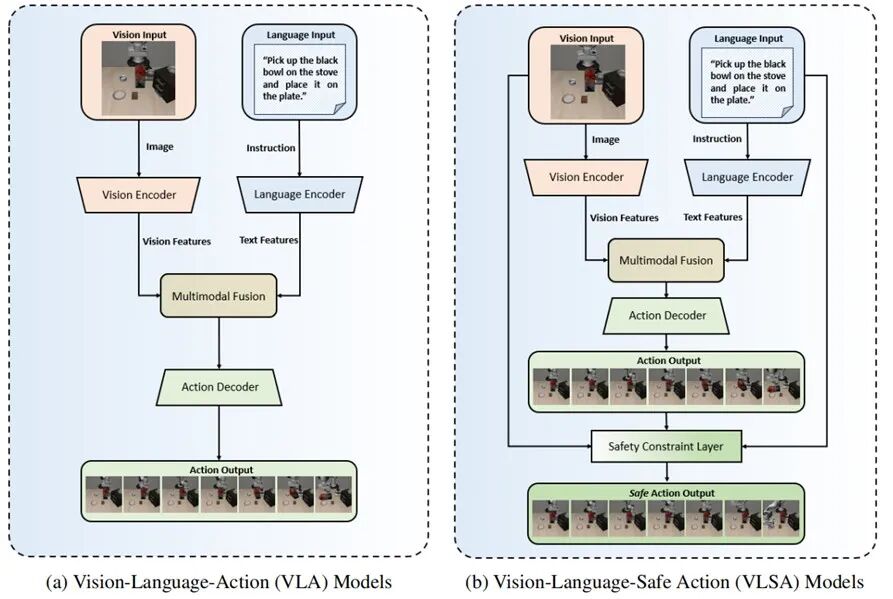
▲VLA 与VLSA 模型的结构对比
核心技术:AEGIS安全执行守护系统
VLSA的核心是AEGIS(Action Execution Guarded by Invariant Safety),它像一位“永远在线却不抢方向盘”的智能副驾驶,在关键时刻精准干预,确保安全无虞:
语义驱动的安全感知
利用VLM理解任务指令(如“将传送带上的电机组件搬运至右侧装配工位”),自动推理出哪些物体是潜在威胁(如正在运转的机械臂、临时堆放的托盘、未固定好的线缆或巡检中的AGV小车);
结合GroundingDINO开放词汇检测器+RGB-D深度图+多视角融合,将文本描述的“危险物”精准定位到3D世界坐标,实现任务对齐的障碍物感知。
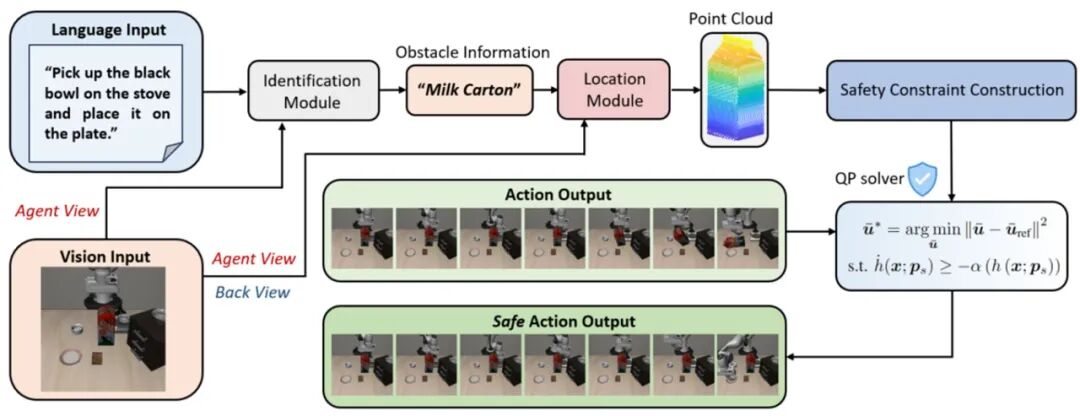
▲AEGIS的流程图
几何约束下的毫秒级安全修正
想象机器人末端和周围的障碍物都不是复杂的形状,而是被简化成一个个“椭球体”。研究人员用了一种聪明的办法:在两个椭球体之间“插”进一个虚拟的平面,系统实时判断两个椭球会不会撞上这个“隔板”。为了让这个方法更灵活、不那么“保守”,还引入了一个“虚拟辅助状态”来动态调整这个平面的方向,让它能更好地贴合实际情况。最终,整个避障策略被转化成一个凸二次规划问题,在平均0.356 毫秒内完成求解,仅占单步控制周期的 1.86%,几乎零开销!

▲机械臂末端与障碍物椭球
只在必要时微调动作,最大程度保留VLA原有的精细操作意图(如端平水杯、轻柔抓取),避免传统避障算法“为了安全牺牲任务”。
严苛验证:SafeLIBERO安全基准发布
为科学评估安全性能,研究团队在主流具身智能基准LIBERO基础上,构建了首个专注于物理安全的测试集--SafeLIBERO:
新增16个任务×2种干扰等级(贴近干扰/路径阻挡);
引入摩卡壶、酒瓶、书本、收纳盒等日常高风险障碍物;
共计1600个随机化测试片段,模拟真实作业场景中的突发碰撞风险。

▲SafeLIBERO测试基准总览
实验结果亮眼
与OpenVLA-OFT和pi_0.5等主流VLA模型相比,AEGIS 模块显著提升了系统的安全性与任务执行能力。
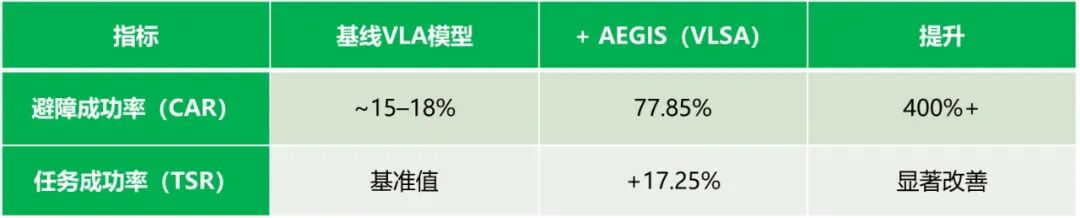
为什么任务成功率反而更高?因为避免了碰撞引发的连锁失败--杯子没打翻、目标没移位、环境未破坏,任务自然更容易完成!
为什么需要专门设计安全层?
因为经典路径规划/人工势场:只看几何,不懂语义,容易破坏VLA的精细动作意图;微调/重训练VLA:成本高昂,且无法覆盖真实世界无限长尾风险,缺乏确定性安全保证;所以要VLSA+AEGIS:以最小侵入式架构,在保留智能性的同时,提供数学可证明的安全边界,真正实现“智能”与“安全”兼得。
面向产业落地:安全是规模化部署的前提
在工厂、制造业、物流仓储等复杂非结构化环境中,安全不是可选项,而是准入门槛。VLSA 架构的轻量化、模块化、即插即用特性,使其可无缝集成到现有VLA机器人系统中,大幅降低安全改造成本,加速具身智能从实验室走向真实场景。

未来,团队将持续拓展 VLSA 在以下方向的能力:
动态障碍物(如移动的人、移动的设备)的实时预测与避让
六自由度(6-DoF)操作中的旋转安全约束
全身协同运动下的多体安全控制
产学研协同,共筑人机安全新生态
此次成果由清华大学安全控制技术研究中心、天创机器人、阿里达摩院三方深度协作完成,标志着具身智能安全体系迈入新阶段。
我们相信:真正的智能,必须是负责任的智能。“守护安全,对抗焦虑"是天创机器人不变的使命。
相关资讯
更多- 迦智科技出海记| 三月韩、泰、印三国工业展会圆满收官
- AGILOX 亮相中奥(常州)创新中心
- 智领欧洲,底座先行丨仙工智能(SEER)四度闪耀德国 LogiMAT
- IMS Gear | 亿迈齿轮CMEF 2026邀请函
- 4月展会预告 | 安德普邀您相聚美国亚特兰大国际物流展览会(4.13- 4.16)& 德国汉诺威工业博览会(4.20-4.24)
- 浙报集团社长姜军一行调研蓝芯机器人:看3D视觉与AI大模型如何重塑智造
- 益佳品质 通行天下--中叉网专访益佳通新能源
- 邀请函 | 擎朗清洁爆品即将亮相荷兰Interclean清洁展!
- 能力升级 | 高密度存储玩家+1
- 未来工厂什么样?“电子电路展”与“先进制造论坛”,库卡给出答案!